Radviz-Sample
title: "Radviz Sample"
author: "Raja CSP Raman"
date: 2019-02-03
description: "-"
type: technical_note
draft: false
import pandas as pd
from yellowbrick.features import RadViz
def load_yb_data(name = 'occupancy'):
folder_path = name+'/'+name
return pd.read_csv('/Users/rajacsp/datasets/yb_data/'+(folder_path)+'.csv')
# Load the classification data set
data = load_yb_data("occupancy")
# Specify the features of interest and the classes of the target
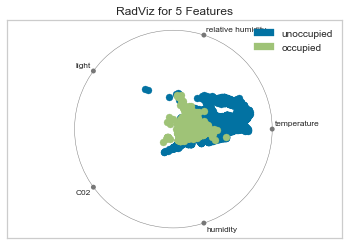
features = ["temperature", "relative humidity", "light", "C02", "humidity"]
classes = ["unoccupied", "occupied"]
# Extract the instances and target
X = data[features]
y = data.occupancy
# Instantiate the visualizer
visualizer = RadViz(classes=classes, features=features)
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.transform(X) # Transform the data
visualizer.poof() # Draw/show/poof the data
Score: 5
Yb-Bikeshare
title: "YB Bikeshare Visualizer"
author: "Raja CSP Raman"
date: 2019-04-20
description: "-"
type: technical_note
draft: false
import pandas as pd
from yellowbrick.features import Rank2D
def load_yb_data(name = 'bikeshare'):
folder_path = name+'/'+name
return pd.read_csv('/Users/rajacsp/datasets/yb_data/'+(folder_path)+'.csv')
data = load_yb_data('bikeshare')
X = data[[
"season", "month", "hour", "holiday", "weekday …
Yb Load Data
title: "YB Load Data"
author: "Raja CSP Raman"
date: 2019-04-20
description: "-"
type: technical_note
draft: false
def load_yb_data(name = 'energy'):
folder_path = name+'/'+name
return pd.read_csv('/Users/rajacsp/datasets/yb_data/'+(folder_path)+'.csv')
data = load_yb_data('spam')
print(data.head(2))
word_freq_make word_freq_address word_freq_all word_freq_3d \
0 0.21 0 …
Yb-Sample
title: "YB Sample"
author: "Raja CSP Raman"
date: 2019-04-20
description: "-"
type: technical_note
draft: false
def load_yb_data(name = 'energy'):
folder_path = name+'/'+name
return pd.read_csv('/Users/rajacsp/datasets/yb_data/'+(folder_path)+'.csv')
from yellowbrick.features import ParallelCoordinates
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer